// Week 18: Optimistic Concurrency
 Hello and welcome back to the SQL Server Performance Tuning series. Last week I have kicked-off the 5th month of the training plan by talking about pessimistic concurrency. Today we will continue by talking about Optimistic Concurrency.
Row Versioning Optimistic concurrency was introduced back with SQL Server 2005 and is based on the principle of Row Versioning. The idea behind row versioning is that readers (SELECT queries) don’t acquire shared locks anymore.
[...]
Hello and welcome back to the SQL Server Performance Tuning series. Last week I have kicked-off the 5th month of the training plan by talking about pessimistic concurrency. Today we will continue by talking about Optimistic Concurrency.
Row Versioning Optimistic concurrency was introduced back with SQL Server 2005 and is based on the principle of Row Versioning. The idea behind row versioning is that readers (SELECT queries) don’t acquire shared locks anymore.
[...]
// Week 17: Pessimistic Concurrency
 Hello and welcome back to the SQL Server Performance Tuning series. Today marks the beginning of the 5th month where we will talk about Locking, Blocking, and Deadlocking in SQL Server.
SQL Server provides you a pessimistic and a optimistic concurrency model that define how concurrent queries are executed. In todays installment I want to give you an overview about the various isolation levels that are part of the pessimistic concurrency model, and next week I will talk in more details about the optimistic isolation levels that were introduced back with SQL Server 2005.
[...]
Hello and welcome back to the SQL Server Performance Tuning series. Today marks the beginning of the 5th month where we will talk about Locking, Blocking, and Deadlocking in SQL Server.
SQL Server provides you a pessimistic and a optimistic concurrency model that define how concurrent queries are executed. In todays installment I want to give you an overview about the various isolation levels that are part of the pessimistic concurrency model, and next week I will talk in more details about the optimistic isolation levels that were introduced back with SQL Server 2005.
[...]
// Week 16: Cardinality Estimation From SQL Server 2014
 Hello and welcome back to the SQL Server Performance Tuning series. In the last week we have talked about some problems with the cardinality estimation process in SQL Server. Today we will continue, and we will have a more detailed look on the shiny new Cardinality Estimator that is introduced with SQL Server 2014.
The new Cardinality Estimator One of the enhancements in SQL Server 2014 is a new Cardinality Estimator.
[...]
Hello and welcome back to the SQL Server Performance Tuning series. In the last week we have talked about some problems with the cardinality estimation process in SQL Server. Today we will continue, and we will have a more detailed look on the shiny new Cardinality Estimator that is introduced with SQL Server 2014.
The new Cardinality Estimator One of the enhancements in SQL Server 2014 is a new Cardinality Estimator.
[...]
// Week 15: Problems With Cardinality Estimation
 Hello and welcome back to the SQL Server Performance Tuning series. In the last 2 weeks you have read about statistics, why they are important and how they look like internally in SQL Server. In today’s installment I’m talking about a few limitations that the current Cardinality Estimation has, and how you can overcome these problems by applying various techniques.
Cardinality Estimation Errors As you have seen last week, SQL Server uses the Histogram and the Density Vector for the Cardinality Estimation, when an execution plan gets compiled.
[...]
Hello and welcome back to the SQL Server Performance Tuning series. In the last 2 weeks you have read about statistics, why they are important and how they look like internally in SQL Server. In today’s installment I’m talking about a few limitations that the current Cardinality Estimation has, and how you can overcome these problems by applying various techniques.
Cardinality Estimation Errors As you have seen last week, SQL Server uses the Histogram and the Density Vector for the Cardinality Estimation, when an execution plan gets compiled.
[...]
// Timetravel in DataBricks
 Yes, you read it correctly. You can travel in time on your data using Azure Data Bricks and DeltaLake. The feature is quite easy to use and comes with a lot of very nice features and business value. Even a value so powerfull that the business does not need to make descissions up front when you are building your data warehouse.
A little word about the background Azure has abopted DataBricks into the Azure Synapse portfolio with seemless integration between all the services from within the umbrella of Azure Synapse.
[...]
Yes, you read it correctly. You can travel in time on your data using Azure Data Bricks and DeltaLake. The feature is quite easy to use and comes with a lot of very nice features and business value. Even a value so powerfull that the business does not need to make descissions up front when you are building your data warehouse.
A little word about the background Azure has abopted DataBricks into the Azure Synapse portfolio with seemless integration between all the services from within the umbrella of Azure Synapse.
[...]
// Week 14: Inside Statistics
 Welcome back to the SQL Server Performance Tuning series. Today I want to talk in more details how Statistics internally are represented by SQL Server. Imagine the following problem: the “Estimated Number of Rows” in an operator in the Execution Plan is 42, but you know that 42 isn’t the correct answer to this query. But how can you interpret the statistics to understand from where the estimation is coming from?
[...]
Welcome back to the SQL Server Performance Tuning series. Today I want to talk in more details how Statistics internally are represented by SQL Server. Imagine the following problem: the “Estimated Number of Rows” in an operator in the Execution Plan is 42, but you know that 42 isn’t the correct answer to this query. But how can you interpret the statistics to understand from where the estimation is coming from?
[...]
// Week 13: Statistics
 Welcome to the 4th month of the SQL Server Performance Tuning series. This month is all about Statistics in SQL Server, and how they help the Query Optimizer to produce a good-enough Execution Plan. Statistics are mainly used by the Query Optimizer to estimate how many rows would be returned from a query. It’s just an estimation, nothing more.
Statistics Overview SQL Server uses within the Statistics object a so-called Histogram, which describes within a maximum of 200 Steps the data distribution for a given column.
[...]
Welcome to the 4th month of the SQL Server Performance Tuning series. This month is all about Statistics in SQL Server, and how they help the Query Optimizer to produce a good-enough Execution Plan. Statistics are mainly used by the Query Optimizer to estimate how many rows would be returned from a query. It’s just an estimation, nothing more.
Statistics Overview SQL Server uses within the Statistics object a so-called Histogram, which describes within a maximum of 200 Steps the data distribution for a given column.
[...]
// Week 12: Parallel Execution Plans
 In this installment of the SQL Server Performance Tuning series I want to talk in more details about Parallel Execution Plans in SQL Server. Executing a query with a parallel execution plan means that multiple threads are used by SQL Server to perform the necessary operators from the execution plan. In the first step I will give you a general introduction to the most common operators used in a parallel execution plan, and afterwards we talk in more details about how SQL Server decides if a parallel plan make sense.
[...]
In this installment of the SQL Server Performance Tuning series I want to talk in more details about Parallel Execution Plans in SQL Server. Executing a query with a parallel execution plan means that multiple threads are used by SQL Server to perform the necessary operators from the execution plan. In the first step I will give you a general introduction to the most common operators used in a parallel execution plan, and afterwards we talk in more details about how SQL Server decides if a parallel plan make sense.
[...]
// Get rid of Helper Queries in Power Query
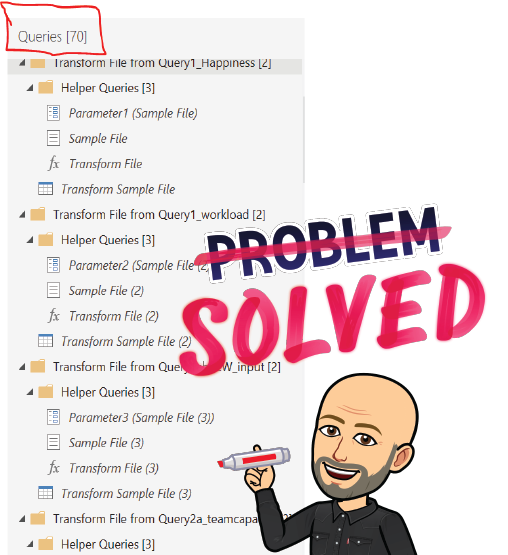 Have you also seen alot of “Helper Queries” in Power Query when working with files from folders? I think it is very cluttered to have all these helpers laying around in the Power Query editor.
What I’m used to see Above is the usual way of Power Query to handle several files in the same folder. The approach is done to have only 1 (usually the first) file to create the schema from.
[...]
Have you also seen alot of “Helper Queries” in Power Query when working with files from folders? I think it is very cluttered to have all these helpers laying around in the Power Query editor.
What I’m used to see Above is the usual way of Power Query to handle several files in the same folder. The approach is done to have only 1 (usually the first) file to create the schema from.
[...]
// Week 11: Recompilations
 Today I want to talk about Recompilations in the SQL Server Performance Tuning series. A recompilation happens when you execute a query, and another activity within SQL Server invalidates the remaining part of the execution plan. In that case SQL Server has to ensure the correctness of your execution plan, and a recompilation is triggered. Recompilations are introducing an additional CPU overhead to your SQL Server.
What are Recompilations? In the first step I want to lay out the differentiation between compilations and recompilations in SQL Server.
[...]
Today I want to talk about Recompilations in the SQL Server Performance Tuning series. A recompilation happens when you execute a query, and another activity within SQL Server invalidates the remaining part of the execution plan. In that case SQL Server has to ensure the correctness of your execution plan, and a recompilation is triggered. Recompilations are introducing an additional CPU overhead to your SQL Server.
What are Recompilations? In the first step I want to lay out the differentiation between compilations and recompilations in SQL Server.
[...]