
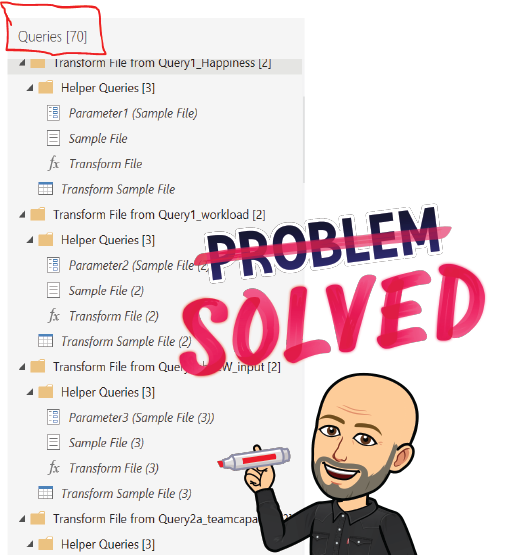
Have you also seen alot of “Helper Queries” in Power Query when working with files from folders? I think it is very cluttered to have all these helpers laying around in the Power Query editor.
What I’m used to see
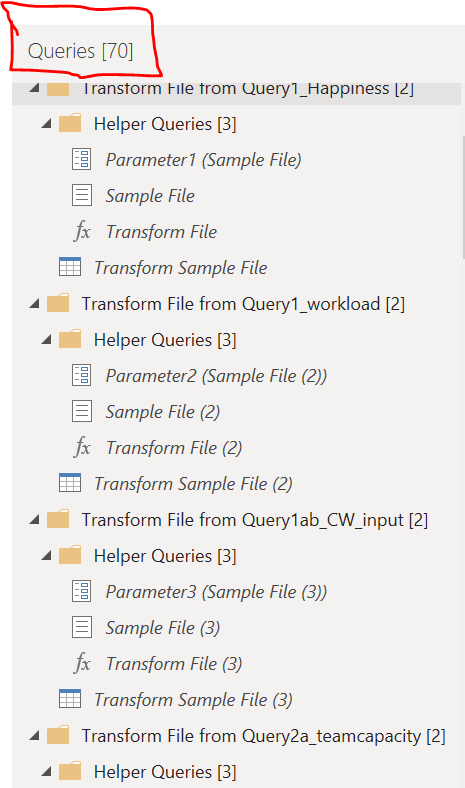
Above is the usual way of Power Query to handle several files in the same folder. The approach is done to have only 1 (usually the first) file to create the schema from. This is also quite ok for at single report using only one or a few folders as sources.
But when you start to have a lot of folders and from this, a lot of helper queries, the approach gets all cluttered and almost unable to read when making changes and debugging.
The cure for CSV
I’ve been frustrated with this for a while now, and finally sat down to create the Power Query to handle this.
It is like below:
let
Source = AzureStorage.Blobs("https://<blobstore>.blob.core.windows.net/<folder>"),
Dataarea = Table.SelectRows(Source, each Text.StartsWith([Name], "<starttext>")),
LatestData = Table.SelectRows(Dataarea, let latest = List.Max(Dataarea[Date modified]) in each [Date modified] = latest),
AddColumnData = Table.AddColumn(LatestData, "CsvContent", each Csv.Document([Content], [Delimiter=";"])),
KeepDataColumn = Table.SelectColumns(AddColumnData,{"CsvContent"}),
ExpandTable = Table.ExpandTableColumn(KeepDataColumn, "CsvContent", Table.ColumnNames(KeepDataColumn[CsvContent]{0}), Table.ColumnNames(KeepDataColumn[CsvContent]{0})),
AddHeaders = Table.PromoteHeaders(ExpandTable, [PromoteAllScalars=true]),
RenameHeaders = Table.RenameColumns(
AddHeaders, List.Zip(
{
Table.ColumnNames (AddHeaders),
List.Transform(Table.ColumnNames (AddHeaders), each Text.BeforeDelimiter(_, " ") )
}
)
)
in
RenameHeaders
I’ll go through each line/segment below and my approach to the solution.
Source
This is quite standard - the source to a blob storage (or any other folder source). Remember to autenticate to the storage account before continuing.
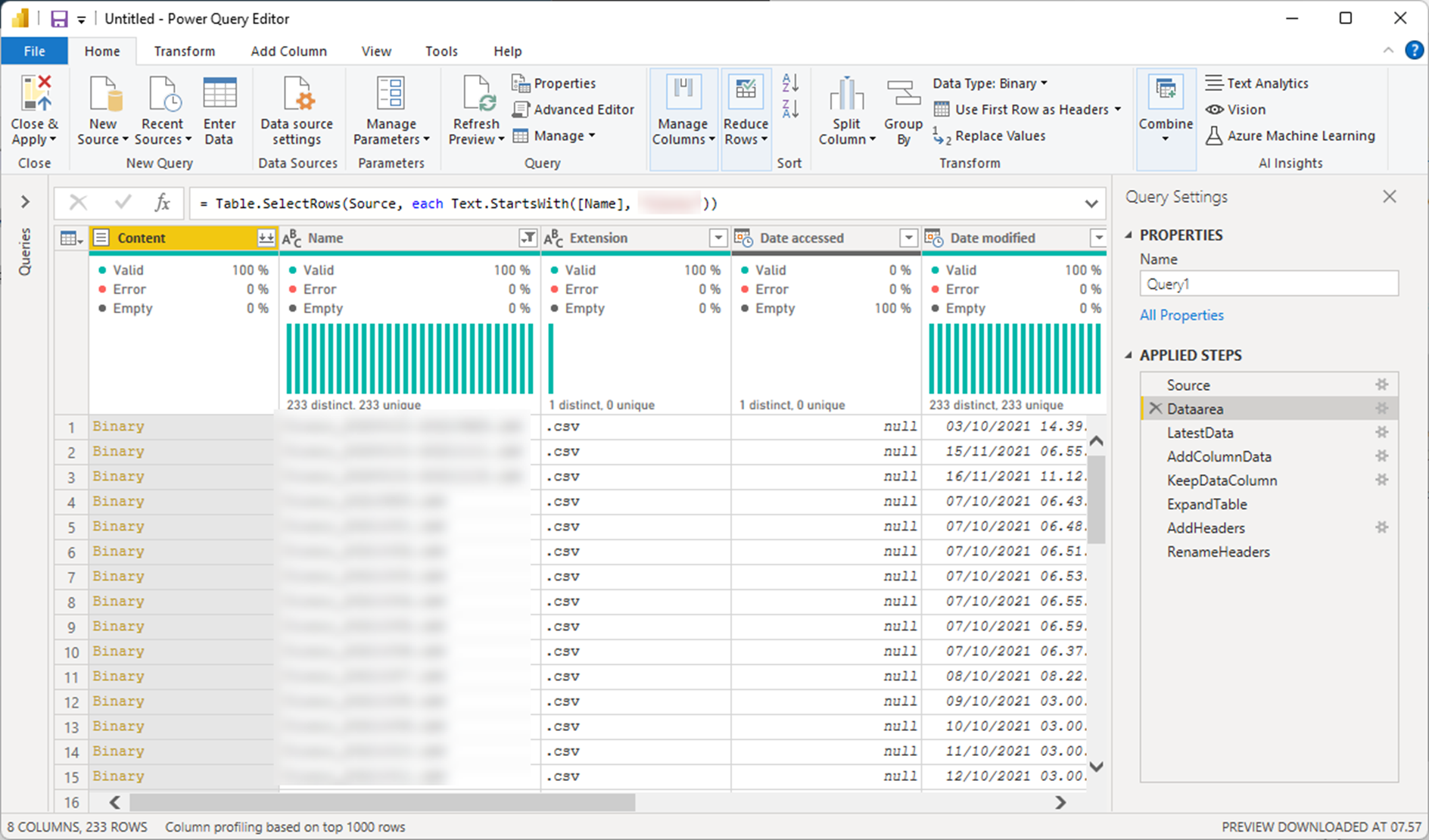
Dataarea
This line selects only the files with the name starting with the text in . If you need it, you can change this to another approach. If you need to select all files in the folder, you can skip this line and go on the next. Remember to change the source-element in the next line.
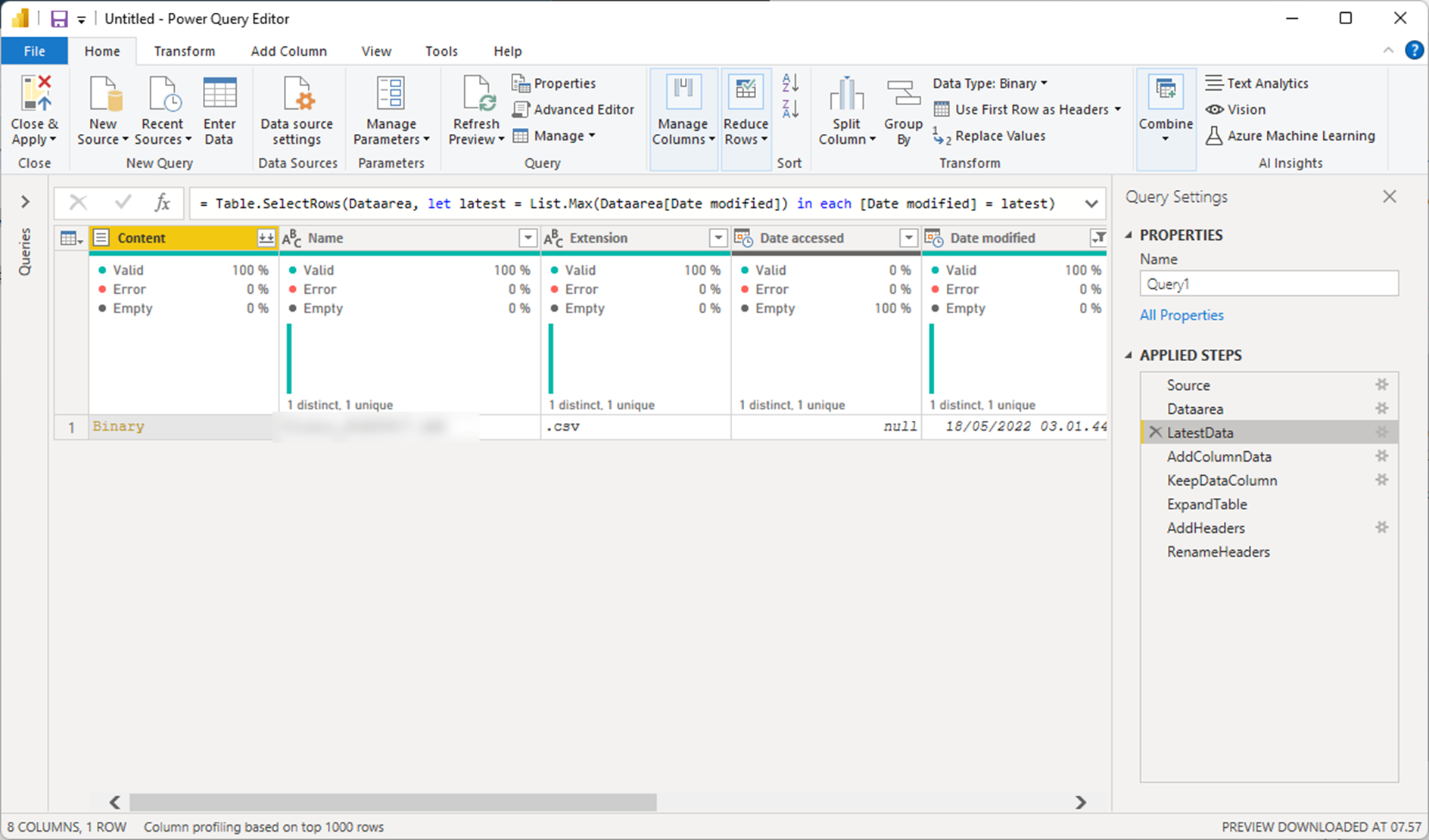
LatestData
This line makes sure to select only the lastest file (based on Modified Date from Blob storage). This in order to help if you have several full-loads in the source and only needs the latest file on the query. If you need all the files in the query, you can skip this also.
AddColumnData
Here I add a new column, based on the default [content]-column. The specific csv-file has semi-colon as column-delimiter. Change this to fit your needs.
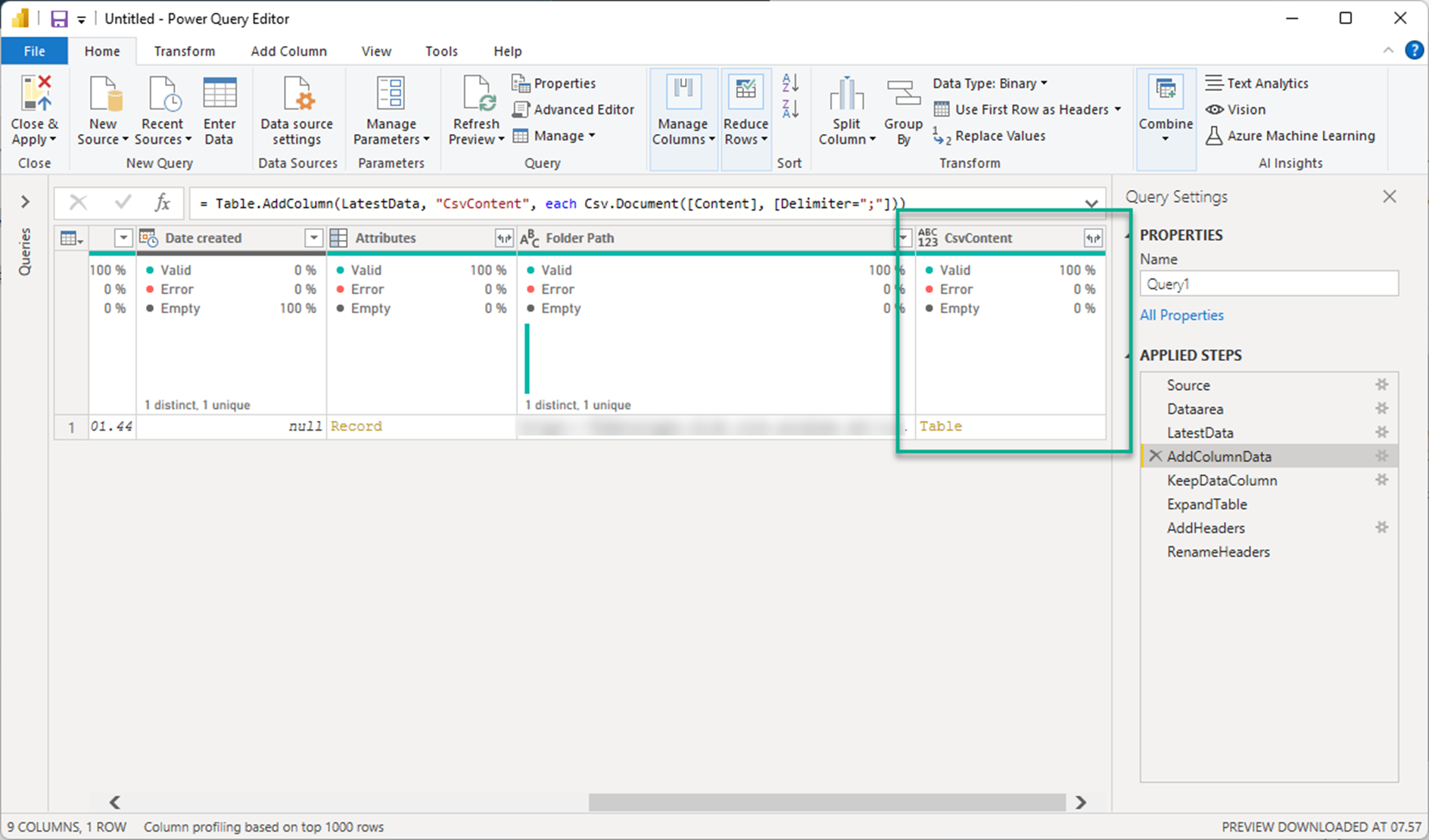
KeppDataColumn
To clean up the UI and datastorage within the Power BI file, I only keep the newly created column, that contains the data I need.
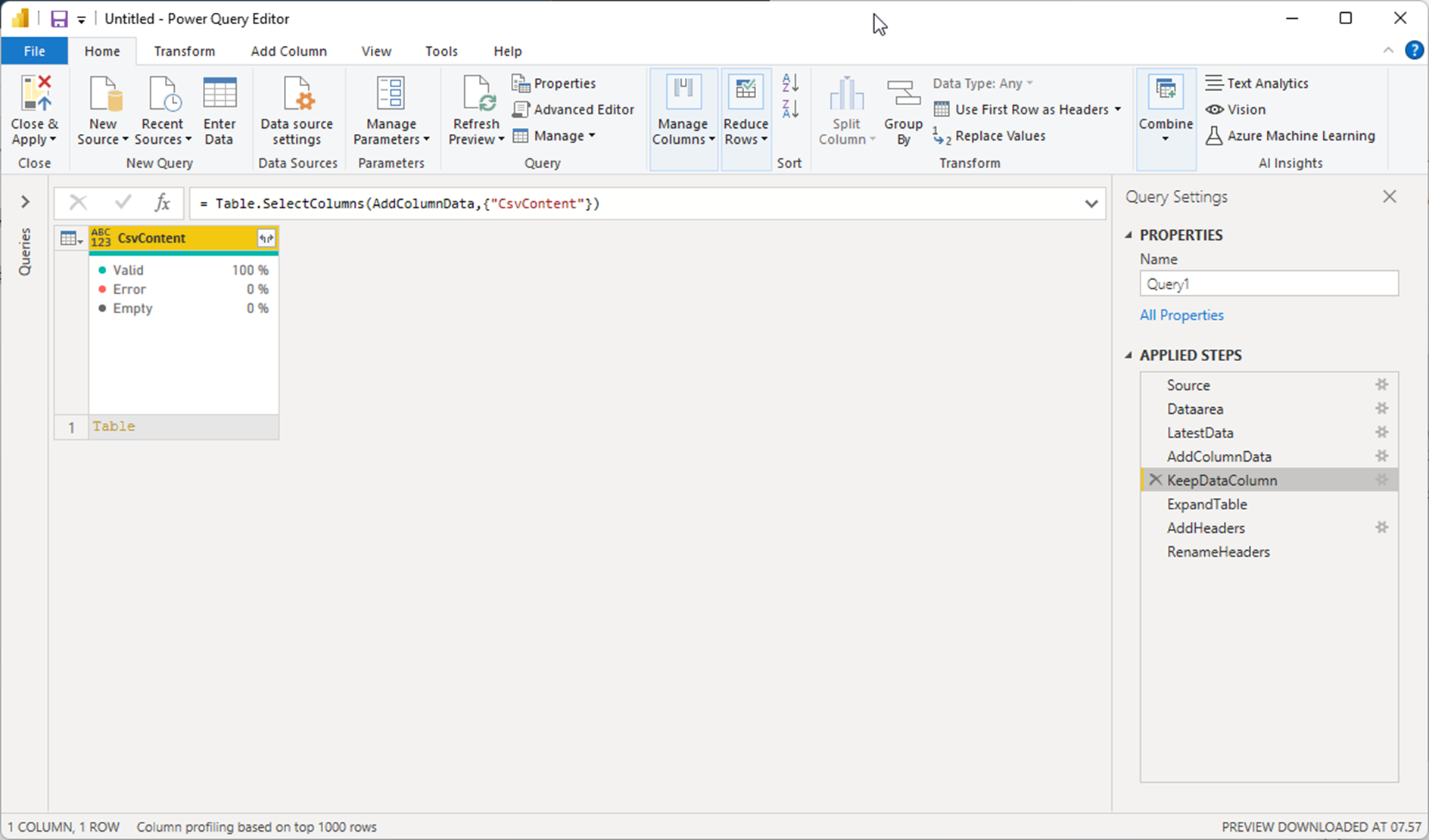
ExpandTable
Here the data-column is exspanded with default columnnames.
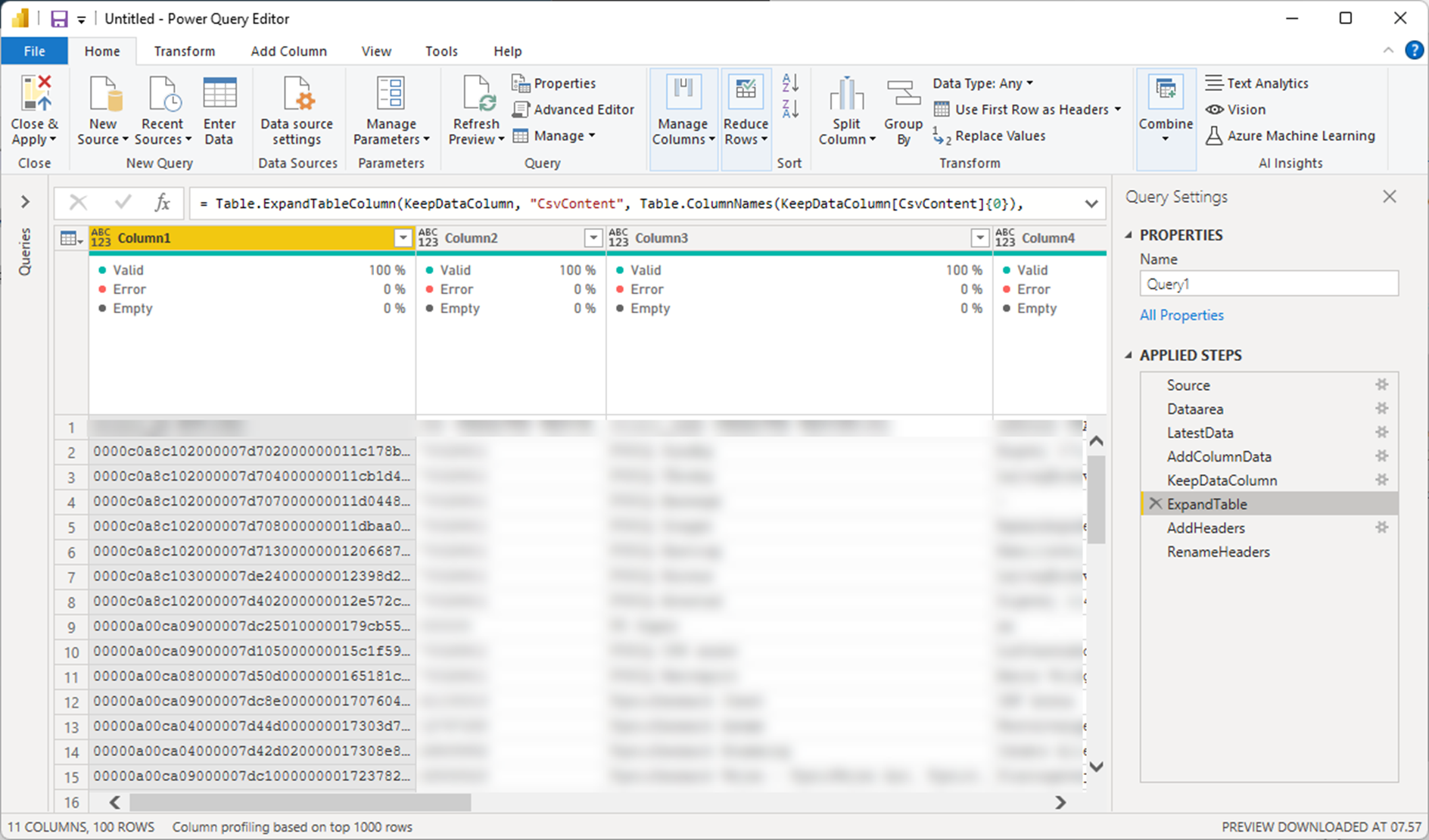
AddHeaders
The headers are now added with promoting the first line to a header line.
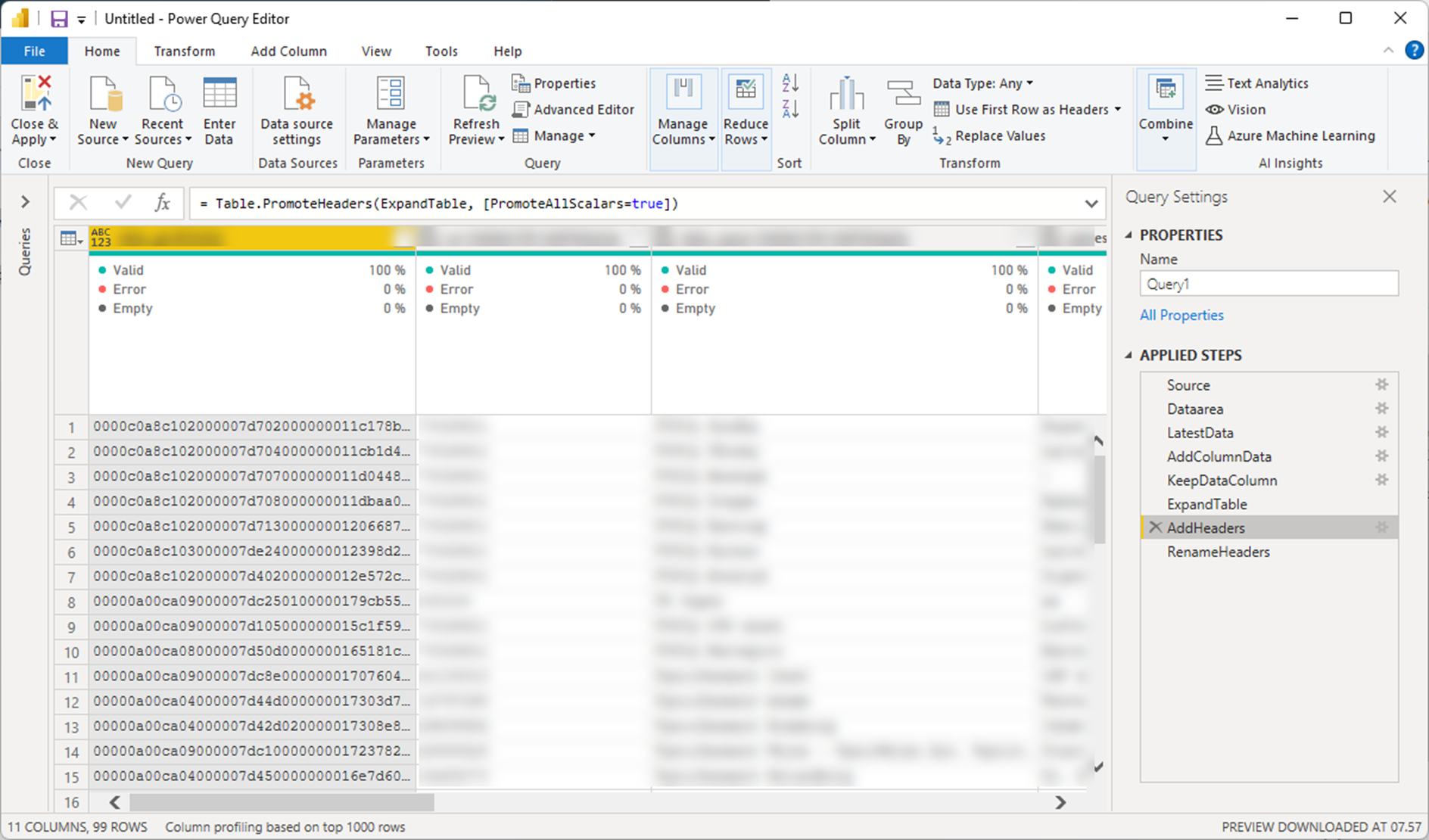
RenameHeaders
In this specific scenario, the file has column names with trailing datatypes (e.g. “Name” NVARCHAR(255)). Here I clean the column based on the first whitespace in the header and remove everything after this.
The backside (if it is a backside)
With above approach you need to specify your datatypes manually. I can’t make up with my self, if this is a good or a bad thing. The bad thing is that it is not done automatically by Power BI (with what follows of possible errors). The good thing is, that I am forced to make a descision about the data types for each column.
I think I like “the good” thing.

Subscribe to my channel
")
")
Free Microsoft Workshops
![]()
- Fabric Analyst
- Power BI dashboard
- Real-Time Intelligence