

Hello and welcome back to the SQL Server Performance Tuning series. In the last 2 weeks you have read about statistics, why they are important and how they look like internally in SQL Server. In today’s installment I’m talking about a few limitations that the current Cardinality Estimation has, and how you can overcome these problems by applying various techniques.
Cardinality Estimation Errors
As you have seen last week, SQL Server uses the Histogram and the Density Vector for the Cardinality Estimation, when an execution plan gets compiled. The model that SQL Server is using here, is a very static one, with a lot of disadvantages and pitfalls. Things will change with SQL Server 2014 - I will talk more about the improvements done here next week.
To give you a concrete example, where the Cardinality Estimation has problems, imagine the following 2 tables: Orders and Country. Every row in the Orders table represents an order placed by a customer (like a fact table in a Data Warehousing scenario), and that table points through a foreign key constraint to the Country table (it acts like a dimension table). And now let’s run a query against both tables to retrieve all sales from UK:
|
|
When you look at the execution plan, you can see that SQL Server has a big problem with the cardinality estimation.
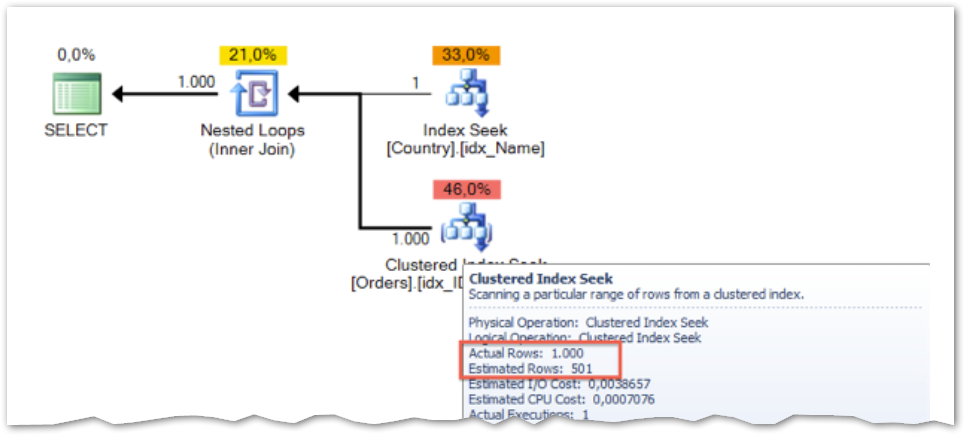
SQL Server estimates 501 rows, and in reality the Clustered Index Seek operator returns 1000 rows. SQL Server uses here the Density Vector of the Statistics Object idx_ID_SalesAmount to make that estimation: the Density Vector is 0.5 (we have only 2 distinct values in that column), and therefore the estimation is 501 (1001 * 0.5). You can fix that specific problem by adding a Filtered Statistics object. This will give SQL Server more information about the data distribution itself, and will also help with the Cardinality Estimation.
|
|
When you now look at the execution plan again, you can see that both the estimated and actual number of rows are now the same.
Correlated Columns
Another problem that you have with the current Cardinality Estimation in SQL Server are search predicates that are correlated to each other. Imagine the following pseudo SQL query:
|
|
When you look as a human at this query, you know immediately how many rows are returned: 0! The company Microsoft doesn’t sell an iPhone. When you run such a query against SQL Server, the Query Optimizer looks on each search predicate independently:
In the 1st step the Cardinality Estimation is done for the predicate Company = ‘Microsoft’. In the 2nd the Query Optimizer produces a Cardinality Estimation for the other predicate Product =‘iPhone’. And finally both estimations are multiplied by each other to produce the final estimation. When the first predicate produces a cardinality of 0.3 and the 2nd one produces a cardinality of 0.4, the final cardinality will be 0.12 (0.3 * 0.4). The Query Optimizer handles every predicate on its own without any correlation between them.
Paul White has also written a very interesting article about that specific problem, and how you can influence the Query Optimizer of SQL Server to produce a better performing execution plan.
Summary
Statistics and the Cardinality Estimation are the most important thing for accurate and good performing execution plans in SQL Server. Unfortunately their usage is also limited, especially in some edge cases. Throughout that article you have seen how you can use Filtered Statistics to help the Query Optimizer to produce a better Cardinality Estimation, and how you can handle correlated columns in SQL Server.

Subscribe to my channel
")
")
Free Microsoft Workshops
![]()
- Fabric Analyst
- Power BI dashboard
- Real-Time Intelligence