

Welcome to the 4th month of the SQL Server Performance Tuning series. This month is all about Statistics in SQL Server, and how they help the Query Optimizer to produce a good-enough Execution Plan. Statistics are mainly used by the Query Optimizer to estimate how many rows would be returned from a query. It’s just an estimation, nothing more.
Statistics Overview
SQL Server uses within the Statistics object a so-called Histogram, which describes within a maximum of 200 Steps the data distribution for a given column. One of the biggest limitations that we have with Statistics in SQL Server is the limitation of the 200 steps (which can be overcome with Filtered Statistics that were introduced back with SQL Server 2008).
The other “limitation” is the Auto Update mechanism of Statistics: with a table larger than 500 rows, a Statistics object is only updated if 20% + 500 column values of the underlying table have changed. This means that your Statistics are getting updated more less as soon as your table grows.
Imagine you have a table with 100.000 records. In this case, SQL Server updates the Statistics object if you have done 20.500 (20% + 500) data changes in the underlying column. If you have a table with 1.000.000 rows, you need 1.000.500 (20% + 500) data changes. The used algorithm here is exponential and not linear. There is also the trace flag 2371 in SQL Server that influences this behavior. See the following link for more information about it.
This behavior can be a huge problem if you are dealing with execution plans that contains a Bookmark Lookup. As you already know, a Bookmark Lookup operator is only chosen by the Query Optimizer if the query returns a very selective result - based on the current Statistics. If your Statistics are out-of-date, and your execution plan is still valid, SQL Server will just blindly reuse the cached plan, and your page reads will just explode. Let’s have a look on a more concrete example about that specific problem.
Stale Statistics
The following script creates a simple table with 1500 records, where we have an even data distribution in the column Column2. In addition we define a Non-Clustered Index on that column.
|
|
When you now perform a simple SELECT * query against that table by restricting on Column2, you will get an execution plan with a Bookmark Lookup operator.
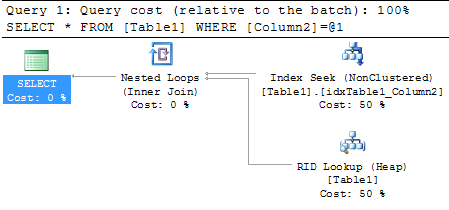
As you will also see from the Index Seek (Non Clustered) operator, SQL Server estimates 1 row (property Estimated Number of Rows), and in reality SQL Server processes 1 row (property Actual Number of Rows). This means we are dealing here with accurate Statistics, and the query itself just produced 3 logical reads.
In our case we are dealing now with a table of 1.500 rows, so SQL Server will automatically update the Statistics object of the underlying Non-Clustered Index when 20% + 500 rows have changed. When you do the math, you can see that we need 800 data changes (1.500 x 0,2 + 500).
What we are now doing in the next step is the following: we are working against SQL Server a little bit, and we are only inserting 799 new records into the table. But the value of the 2nd column is now always 2. This means we are now completely changing the data distribution of the table in that column. The Statistics objects thinks that 1 record is returned, but in reality we are getting back 800 rows (1 existing rows + 799 newly inserted rows):
|
|
When you now run the identical SELECT statement again, SQL Server reuses the cached Execution Plan with the Bookmark Lookup. This means now that the Bookmark Lookup in the Execution Plan is executed 1.500 times, for every record once! This will also cost a lot of logical reads, SQL Server now reports 806 page reads! As you can see from the following picture, the Estimated Number of Rows are now far away from the Actual Number of Rows.
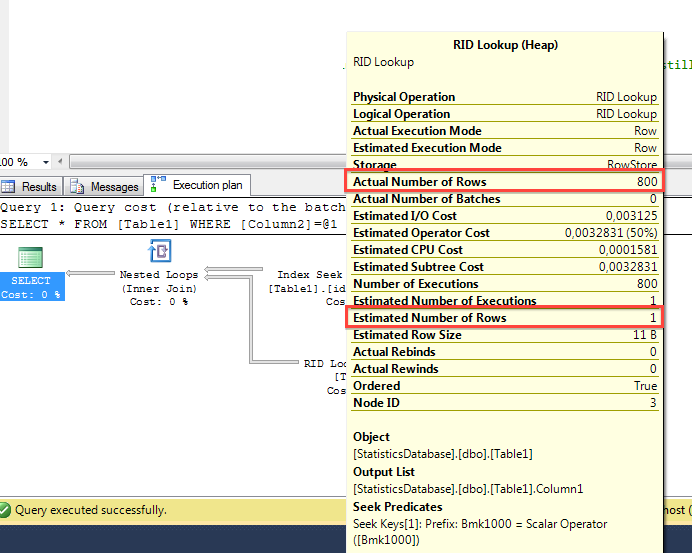
That’s one of the problems that you introduce with stale Statistics in SQL Server.
Summary
Today I have given you a brief overview in the SQL Server Performance Tuning series about Statistics in SQL Server. As you have seen, stale Statistics can introduce serious performance problems with cached, reused execution plans.

Subscribe to my channel
")
")
Free Microsoft Workshops
![]()
- Fabric Analyst
- Power BI dashboard
- Real-Time Intelligence