

Welcome back to the SQL Server Performance Tuning series. Today marks the start of the 3rd month of the training plan, which is all about Execution Plans in SQL Server. Execution Plans are the most important concept that you have to understand in SQL Server to make effective changes to improve performance for your queries. For that reason I’m giving you today a general introduction to Execution Plans in SQL Server, and how you can interpret and read them.
Why Execution Plans?
A lot of people are always asking me why there is a need for Execution Plans in SQL Server. We have a SQL Server query, and why SQL Server needs an Execution Plan? Why is SQL Server not just executing the query itself? To answer that specific question we have to talk a little bit more in details about the SQL language. The SQL language (and also T-SQL in SQL Server) is a declarative language. You are describing in a logical way which data you want to have from your database (SELECT query), or which data you want to change in your database (INSERT, UPDATE, DELETE queries). Just look on the following query:
|
|
With that query you are just telling your database that:
- You want to retrieve data from table A and B
- Both tables should be joined together through the column ID in both tables
- Rows in table A should be filtered out on column X
You are only describing through a SQL statement how the result of your query should look like that you are expecting from your database. With the SQL statement you only specify the result, nothing more. You are not telling SQL Server in any way how to execute the query itself that produces that requested data.
You are always interacting with SQL Server in a logical way, describing what pieces of data you want to retrieve, or what pieces of data you want to change. But SQL Server itself needs a physical Execution Plan that describes step by step how to gather or change that data. The Execution Plan is just the strategy picked by the so-called Query Optimizer to process your SQL query.
There is also a very nice analogy to our real life: imagine you want to travel from one city to another. When you say that you are traveling from London to Paris, you have just defined a logical expression. Of course, that logical expression can have multiple physical permutations:
- You can walk from London to Paris
- You can go by bicycle
- You can go by car/train/airplane
It doesn’t matter which option you are picking here, you have for every different permutation again multiple different permutations. Your possible options are just exploding. And your job is to find the option which has least associated cost with it: you will mainly pick an airplane. And the same job has the Query Optimizer in SQL Server: the Query Optimizer will pick that Execution Plan that has the smallest amount of work to perform to satisfy your query. And the challenge of the Query Optimizer is to find that good enough Execution Plan from the overall so-called Search Space - and that search space can be very huge the more tables and indexes are involved in your queries!
How to read Execution Plans
When you deal the first time in your life with Execution Plans, you have mainly a huge problem with them: you are not able to understand and interpret them correctly. Just have a look on the following Execution Plan.
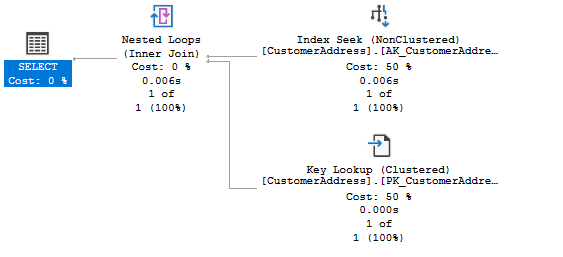
As you can see from the previous picture, every Execution Plan contains multiple steps, so-called Operators in SQL Server. And these operators are called row-by-row from SQL Server. This means that rows are flowing from the right to the left in the Execution Plan. In our case SQL Server executes in the first step the Index Seek (Non Clustered) operator on the table Address. Every record from the scan goes into the Nested Loop operator, which comes after the scan. And for every retrieved record, SQL Server performs a Key Lookup (Clustered) operator (a Bookmark Lookup) on the table Address. If there is a matching row, the row is passed into the SELECT operator, which finally returns the result back to the application.
As you can see from this description, it’s easier in the beginning to read an Execution Plan from the right side to the left side, because rows are also flowing in that direction through the Execution Plan. An Execution Plan is physically still executed from the left to the right side. We are just looking in a logical way on our Execution Plan, when we follow the rows from the right to the left side.
I hope that this approach will help you in having a better understanding how you can read and interpret Execution Plans. If you want to have a more detailed look on the various operators that an Execution Plan supports in SQL Server, I highly recommend the free ebook Complete Showplan Operators by Fabiano Amorim.
Summary
In this installment of the SQL Server Performance Tuning series I have clarified why we need Execution Plans in SQL Server, and how they can be read and interpreted by you. As you have seen, we are always communicating with SQL Server in a logical way: we describe through SQL queries which data we request from our database, or which data we want to change.

Subscribe to my channel
")
")
Free Microsoft Workshops
![]()
- Fabric Analyst
- Power BI dashboard
- Real-Time Intelligence