

In the last week I have talked about Clustered Indexes in SQL Server. When you define a Clustered Index on your table, you are physically sorting your table data on the provided Clustered Key column(s). In addition to a Clustered Index, you can also define multiple Non-Clustered Indexes (up to 999) on a table in SQL Server.
A Non-Clustered Index is just a secondary index that you can define on some columns of your table. You can again compare a Non-Clustered Index with a book. But this time you have to think about a book like a T-SQL Language Reference. The book itself is our Clustered Index, means the different commands are physically sorted by their name. And in the back of the book, you have an index. When you are searching for a specific command (like CREATE TABLE), you can use that index in the back of the book to find out where a specific command is described in more detail.
The book gives you here a lookup value - the page number - where you can find further details about the command. The same concept applies to SQL Server: when you are accessing your table through a Non-Clustered Index in the Execution Plan, SQL Server also gives you in the leaf level of the Non-Clustered Index only a lookup value where you can find further details about the record. SQL Server needs that lookup value to navigate from the Non-Clustered Index into the Clustered Index or Heap Table to find the additional requested columns from the record that are not part of the Non-Clustered Index This is a so-called Bookmark Lookup in SQL Server. Let’s talk a little bit more about them.
Bookmark Lookups
Every time when you access a Non-Clustered Index in the Execution Plan of a query, and you reference columns in your query that are not part of the Non-Clustered Index, SQL Server has to perform a Bookmark Lookup in the Execution Plan. The following picture shows a typical Bookmark Lookup in an Execution Plan:
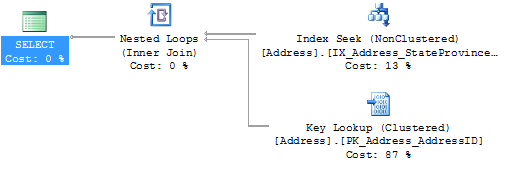
As you can see, SQL Server performs a Non-Clustered Index Seek operation on the table Person.Address. And in addition SQL Server retrieves all the other requested columns through a Key Lookup (Clustered) operation from the underlying Clustered Table. This seems to be a very cool feature of SQL Server, but in reality Bookmark Lookups are very, very, very DANGEROUS!
They can lead to Bookmark Lookup Deadlocks, and their performance will suffer with old out-of-date Statistics, or when you have to deal with Parameter Sniffing problems. Bookmark Lookups can only occur in combination with Non-Clustered Indexes. For that reason I’m also talking next week how we can avoid Bookmark Lookups in our Execution Plans, and why SQL Server sometimes just ignores your almost perfect Non-Clustered Index.
Clustered Key Dependency
As I have said earlier, SQL Server stores in the leaf level of the Non-Clustered Index a lookup value that points to the record that is stored in a Clustered Table or Heap Table. When you have defined a Non-Clustered Index on a Heap Table, that lookup value is called Row-Identifier lookup value. It’s just an 8 byte long value, which stores the page number (4 bytes), file id (2 bytes), and the slot number (2 bytes) where your record is physically stored.
If you have defined your Non-Clustered Index on a Clustered Table, SQL Server uses the Clustered Key value as the lookup value. This means that your careful (?) chosen Clustered Key column is part of EVERY Non-Clustered Index. There is a huge dependency between the Clustered and a Non-Clustered Index. And the Clustered Key is the most redundant data in your table. Therefore you have to think really carefully when you choose your Clustered Key column(s). Because of that strong dependency, an optimal Clustered Key should have 3 properties:
- Unique
- Narrow
- Static
Keep that always in mind that your Clustered Key is ALWAYS present in the Non-Clustered Index!
Summary
Non-Clustered Indexes are very important for improving performance of your queries. When when you are introducing Bookmark Lookups through a not very well designed Non-Clustered Index, you can introduce huge problems and side-effects in your database. If you want to have a deeper understanding about the used structures in a Non-Clustered Index.

Subscribe to my channel
")
")
Free Microsoft Workshops
![]()
- Fabric Analyst
- Power BI dashboard
- Real-Time Intelligence