

One of the new features in SQL Server 2016 – and there is a lot – is the ability to stretch the on premise databases to an Azure environment.
This blogpost will cover some of the aspects of this – including:
- Primarily setup – how to get started
- Monitoring state of databases that are in ‘stretch mode’
- Daily work with stretch databases
- Backup – what’s good to know
With the release of SQL Server 2016, the new feature called stretch database is also released. The feature lets you as a database administrator, make databases stretch (read: copy old data) to an Azure environment. The data is still able to respond to the normal queries that are used, in other way; there is no need to change the current setup for existing applications and other data-contracts to use this feature.
So when is the stretch database something you should consider
When you only sometimes need to query the historical data The transactional data that are stored needs all historical data The size of the database tables are growing out of control (but not an issue of bad design – then you need to take other actions…) The backup times are too long in order to make the daily timeslots for maintenance If you have one or more marks on the above list, then you have a database that are candidate for stretching into Azure.
A typical database in stretch mode are a transactional database with very large amounts of data (more than a billion rows) stored in a small number of tables.
The feature is applied to individual tables in the database – but a need for enabling the feature on database level is a prerequisite.
The limitations
No free goodies without limitations.
There are a list of limitations to a stretch database. Two types of limitations, datatypes and features.
The datatypes that are not supported for stretch database is:
- filestream
- timestamp
- sql_variant
- XML
- geometry
- geography
- hierarchyid
- CLR user-defined types (UDTs)
The features that are not supported:
- Column Set
- Computed Columns
- Check constraints
- Foreign key constraints that reference the table
- Default constraints
- XML indexes
- Full text indexes
- Spatial indexes
- Clustered columnstore indexes
- Indexed views that reference the table
Therefore, it is advisable to have an agreement with your developers if you plan to use the stretch feature. It is more likely that they can code without the above lists, but if they already have implemented features, and needs to work around them, then you are not in good standing for a while.
Security
In order to handle and maintain the stretch feature the current user must be a member of the db_owner group and CONTROL DATABASE permissions is needed for enabling stretch on database level.
Setup – how to get started
First, get an Azure account. If you not already have one. Then…
A small change in sp_configure is needed to get the feature ready.
|
|
Enabling the database
It is a prerequisite to enable the database for stretch in order to enable its tables.
It is pretty straight forward – just right-click the database –
choose tasks and select ‘Enable database for stretch’: 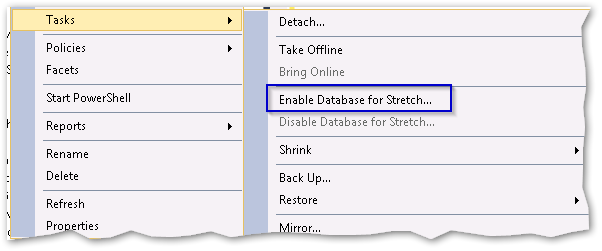
Then the SQL Server asks you to sign in to your Azure environment.
You need to choose a set of settings for your stretch database in Azure – including:
- Location for the server
- Credential for the server
- Firewall rules
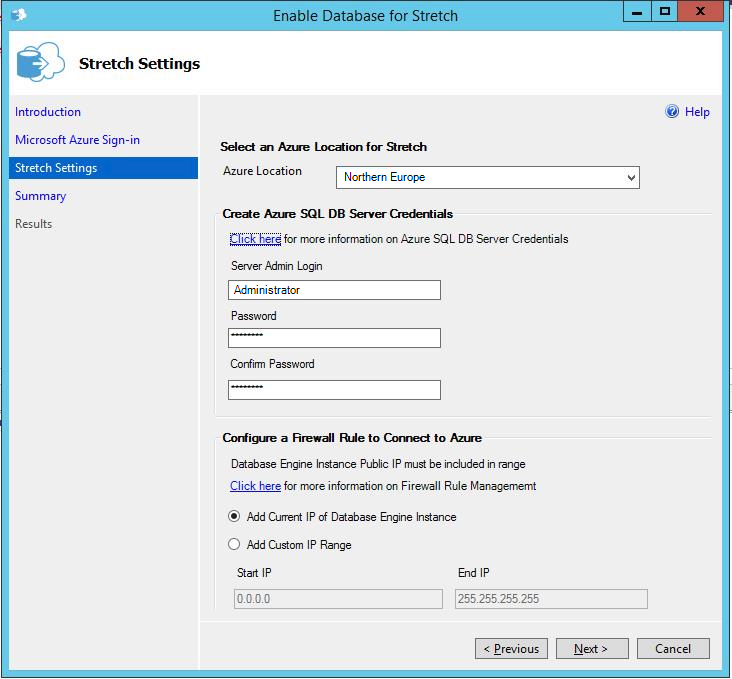
There is a summary page with all info – when complete, just hit ‘Finish’.
Note: the current applications and data-contracts are NOT able to access the data in Azure directly. The only way to access this data is through the normal on premise database. This database then makes the call to access the Azure database or not based on the current configuration and state of migration (see below for help in the latter).
Enabling tables for stretch
As easy as the database, so is the tables.
Right-click the table that you want to stretch – choose ‘Stretch’ and ‘Enable Stretch’.
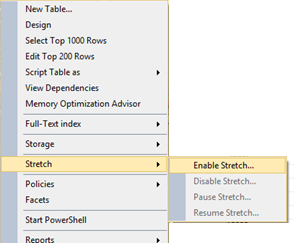
As seen on the screenshot you can also here do the following tasks: Disable, Pause and Resume stretch. All 3 hopefully self-explainable.
Monitoring the state of databases and tables in stretch mode There is released a list of Dynamic management views (DMVs) and updated to existing catalog views to help with the work of monitoring the state of stretch databases.
The DMV sys.dm_db_rda_migration_status shows you the current state, in batches and rows, of the data in the stretched tables. For more information, refer to MSDN: sys.dm_db_rda_migration_status.
The catalog views sys.databases and sys.tables now also contains information about the stretch feature on each part respectively. See more as MSDN: sys.databases and sys.tables.
To view the remote databases and tables for stretch data use the two new catalog views sys.remote_data_archive_databases and sys.remote_data_archive_tables.
A big note for the current CTP 2.2 release: This release only supports the stretch data for entire tables. This meaning that an architectural decision needs to be taken to move historical data to separate tables. I will assume that the final release will contain a query based configuration in order to find and detect the historical data to be moved to the Azure environment.
Backup and restore
The backup and restore is the same as before the stretch feature. The same strategy must be taken and also the same precautions for data storage in Azure.
One must keep in mind that the on premise backup only happens with on premise data.
The restore process adds a step to the checklist when restoring a database with stretch enabled.
Upon the end of restore a connection to the stretched database in Azure must be reestablished with the stored procedure sys.sp_reauthorize_remote_data_archive.
When this SP is executed, the vertical arrow on this
illustration is reestablished: 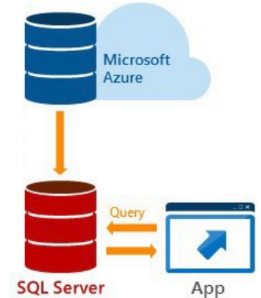
Conclusion
The stretch database feature is a very nice and good feature to get with the release of SQL Server 2016. It enables the DBA to handle historical data and storage capacity without having the consult the developers and/or architects of new solutions. Also current applications and solutions can be configured to use this new feature.

Subscribe to my channel
")
")
Free Microsoft Workshops
![]()
- Fabric Analyst
- Power BI dashboard
- Real-Time Intelligence