
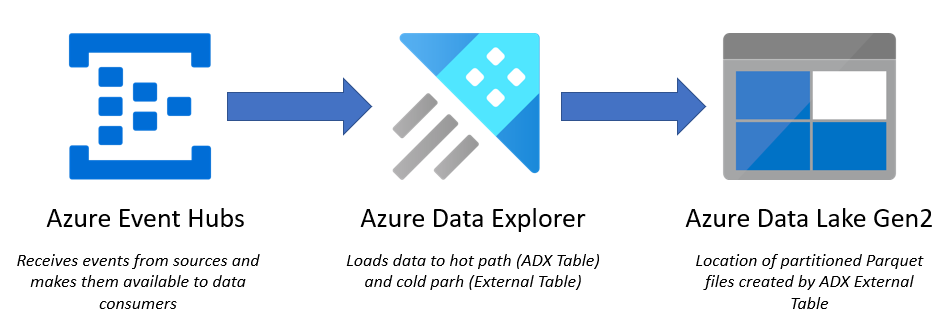
When working with Azure Data Explorer (ADX or Synapse Data Explorer (SDX)) the data is often streamed to the Kusto engine to be available almost instantly to the end user or application accessing the Kusto engine.
This is really the power of the Kusto engine - but it would also be really good to have the data off loaded to a blob storage as Parqute files for other processes (ex. the Data warehouse) to use the same data.
This process then leverages the strength from both platforms. Kusto to query the streaming data and data lake as the cost effective and long-term storage.
Benefits from this approach is to keep the data stored in the Kusto cluster to what is needed for the business to do the analytics based on the real-time data. A Kusto cluster is made of 2 (or more) VMs in Azure with a configured storage capacity (read: not unlimited).
The setup
To setop the off load of data from Kusto cluster to Azure Data Lake, I’ll use the feature of External Table in Azure Data Explorer.
An external table in ADX is, for comparison, more or less the same feature as an external table in Synapse. A pointer to a storage account with a specific file format.
In order to be allowed to create an external table in Kusto, you need to enable the ExternalTable feature under AllowedUsages in the policy on the database.
Below examplse first gets the ObjectId for the database and then enables the “ExternalTable” feature for that database.
// Check database policy for Managed Identity
.show database <database name> policy managed_identity
| mv-expand d = todynamic(Policy)
| project d["ObjectId"],
d["DisplayName"],
d["AllowedUsages"]
// Alter databse policy to allow usage of Managed Identity to connect to External Tables
.alter database <database name> policy managed_identity ```
[
{
"ObjectId": "Paste ObjectId from previous query here",
"AllowedUsages": "DataConnection, ExternalTable"
}
]
With the feature now enabled we also need to make sure that the service principal from the Kusto cluster has write access to the blob storage. This is done within your Azure portal.
Remember to add the role of “Storage Blob Data Contributor” to the service principal.
Now we need to create the actual external table to the database.
An example scrip to do that is found below:
.create external table external_table
(
<columnname>:<datatype>
,<columnname>:<datatype>
,<columnname>:<datatype>
...<continue to what fits...>
)
kind=storage
partition by (Month:datetime = startofmonth(<table's timestamp>))
pathformat = (datetime_pattern("'year='yyyy'/month='MM", Month))
dataformat=parquet
(
h@'abfss://<add-container-name-here>@<add-storage-account-name-here>.dfs.core.windows.net/adxExport/external_table;managed_identity=system'
)
The column definition from above needs to fit the table from your Kusto cluster that is exported. Or else you’ll end with a myriad of errors.
This creates the pointer of data from the Kusto cluster to the Blob Storage account with a main folder of “external_table” and a partition scheme of month and year.
After this we need to ensure that data is read from the actual Kusto table and exported to the external table defined above.
We do this with a special (read: for me not so used) function-type called “continuous-export”.
Example script for this task:
// Create an export that produces parquet files containing events every 10 minutes
.create-or-alter continuous-export export_data
over (data_clean) //this is your source table from Kusto
to table external_data //this is the external table name as defined in above script
with
(intervalBetweenRuns=10m) //this is the interval - here 10 mins
<| data_clean //again a pointer to your source table from Kusto
Now data is automatically copied to the Azure Blob storage account every 10 mins in Parquet files and partitioned in months and years as configured in the export functionality above.
The last thing to do (if needed) is to setup a deletion proces to remove old data from the Kusto cluster. More on this in a later post on this blog.

Subscribe to my channel
")
")
Free Microsoft Workshops
![]()
- Fabric Analyst
- Power BI dashboard
- Real-Time Intelligence