// Learn Kusto - Week 1

Hello, and welcome to the first issue of Learn Kusto. In this serie of blogpost I’ll guide you from zero to hero on using the Kusto query language and in the same time you’ll learn how to implement and use the methods to do live reporting on timeseries data.
In this first edition I’ll start with the engine and the setup from Microsofts implementation with Azure Data Explorer and the Kusto query engine.
The EngineV3
The current implementation of the Kusto engine in Azure is named EngineV3. With this version (compared to older versions) the engine is optimised around storage formats, indexes and data statistics to create even faster execution plans.
The EngineV3 version still uses the “old” EngineV2 and rowstore, so no update to existing scripts is needed.
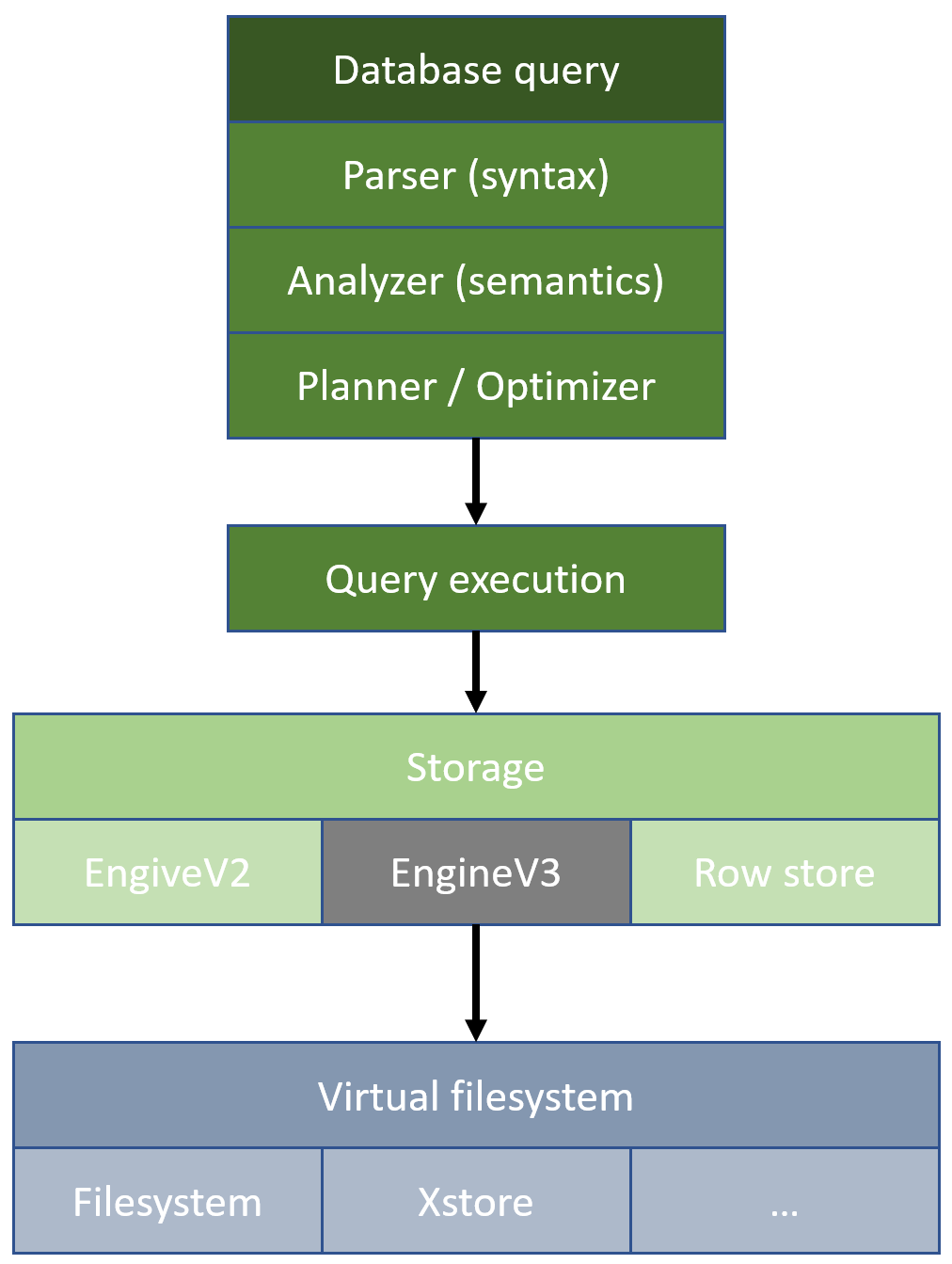
Below is a simplified engine drawing. All queries goes through some layers of checking if everything is ok (Parser and Analyzer) for the Planner and Optmizer to take over and generate a good execution plan.
Then the actual engine takes over and starts the Query Exection reading data from the Storage engine and data from the Virtual Filesystem.
Data ingestion
All data is ingested into socalled shards. A shard is a specific partitionstrategy where the data is splitted into several horisontal slices of the table. In the scope of the engine, each shard is normally containing a few million rows (yes, this is alot of data if “a few million rows” are a small part of a table). The benefit of this sharing, is that each shard is indexed and encoded independant of other shards from the same table
These Shards are stored on two different storage modes - ultra fast SSD and directly in memory. The planner and optimizer then makes sure to create a highly parallelized query.
Summary
This was the first week of a long series of posts to learn the Kusto query language and the tools to use for development. I hope you enjoyed this introduction and are willing to join the journey. Don’t forget to sign up for news in this series of blogs using the form below.
☕