

In every project on Business Intelligence there comes a time when the code needs to be deplyed to the production environment. No more development, no more manual work. It is time for dynamic partitioning.
But what about the partitions on the tabular cube? Do we really need to tell and learn the DBA how to handle that on a periodic plan?
The answer is simple: No!
Thanks to the XMLA language, the DMV’s for SSAS instances (both tabular og multidimensionel) and SSIS we can do the partitioning dynamic based on the current data in the datawarehouse.
In below examble I’ve made partitions for every month, but as always you need to take the current architecture, dataflow, data deliveries etc into account when creating your sollution.
Here we go:
We need a table in order to keep track on the partitions and their metadata. Also a table to hold data from existing partitions in the Tabular cube:
In SSIS I’ve created a dataflow from the SSAS Tabular instance with the list of partitions on the table I want to partition to the table ExitingPartitionsList. We can do this thanks to the DMV’s for SSAS which also works for Tabular instances – see this link for further information.
The SQL-statement to get list of partitions (reference to msdn):
The tableID is found in the tables properties (right-click and
choose ‘Properties’): 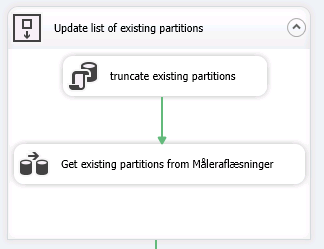
The controlflow looks like this. I hope it is somewhat
self-explainable: 
Now we need to take a look at the naming convention of the partitions. There is a need for the partition-name to have a suffix that tells the span of the partition. I’ve choosen [Tablename]-[fromdate]-[todate]. And in order to get usable data from the previous dataflow, I’ve made a view as below:
Giving this output:
My facttable (Måleraflæsninger) has a field that is used to filter the partition. In this case it is ‘datekey’. In order to get all possible partitions that are needed for the project I’ve made this view:
Take notice that I’ve made the dates end at last day of the month. This is going to be used to generate the view for the partitions later on. Based on these two views we can now generate the list of partitions that needs to be created in the Tabular project:
Now I need to generate a set of XMLA’s. One to create a partition and one to process a partition. The easiest way to get these is to script them from the GUI in the SSAS Tabular instance.
1: Right-click the table that I’m working with and selecting ‘Partitions…’
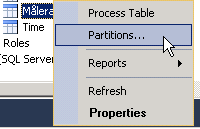
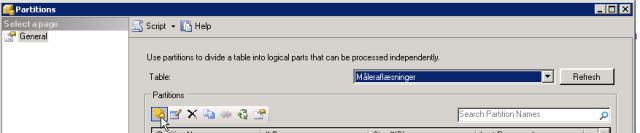
2: Click ‘New partition’
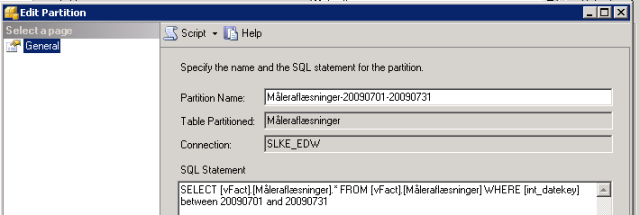
3: Here specify the name – remember the convention – and the SQL statement. Here it is important to remember the filter criteria for the partitions. In this case it is one partition for every month.
- Finally click the Script buttom and ‘Script Action to New Query Window’
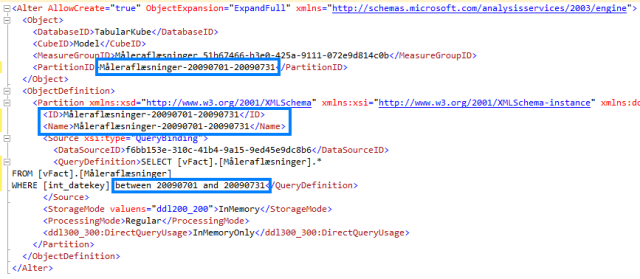
Result – the areas I’ve highlighted are the ones that we need to parameterize in SSIS – more to come on that part in a bit.
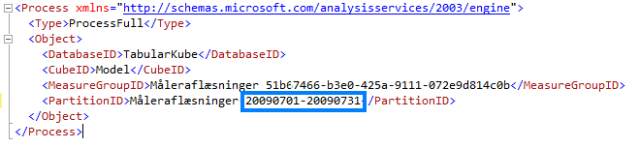
The same way I’ve made a XMLA script to process the partition – the highlighted area is, again, to be parameterized later:
Now we need to go to SSIS and make the logic and steps to accuire the dynamic partitioning.
First of all we need to make sure that all partitions that should be in the model also exists, and if they do not exists, we’øll create them.
The SSIS project now needs some variables as listed below:
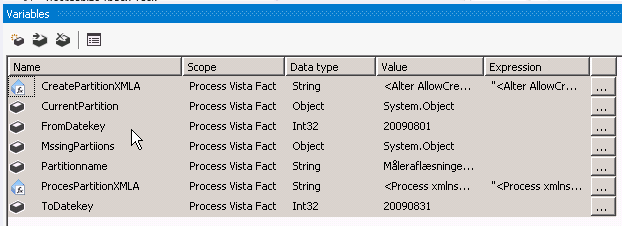
The scope varies from project to project.
After all the variables has been defined, we need to make the two XMLA-variables as Expressions.
In the Expression builder add below codes to the respective variable:
CreatePartitionXMLA – replace the meta-data with the one that matches your sollution:
ProcessPartitionXMLA – replace the meta-data with the one that matches your sollution:
Now we are all set and just need to build the package.
The focus is now on a container like this:
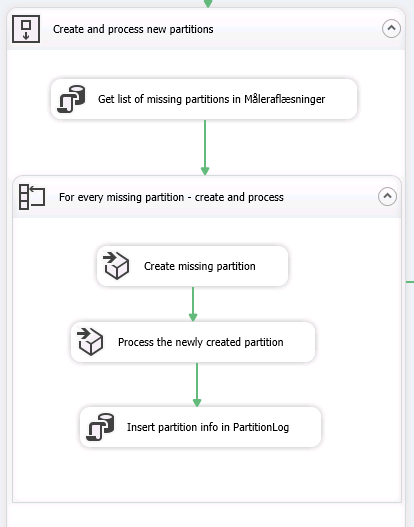
The steps are to get all the missing partitions from our defined view and loop the result with both Create partition, Process partition and Insert data to PartitionLog.
Step 1:
Define a SQL task with the following statement:
Define the output to ‘Full resultset’ and map the result to the variable MissingPartitions.
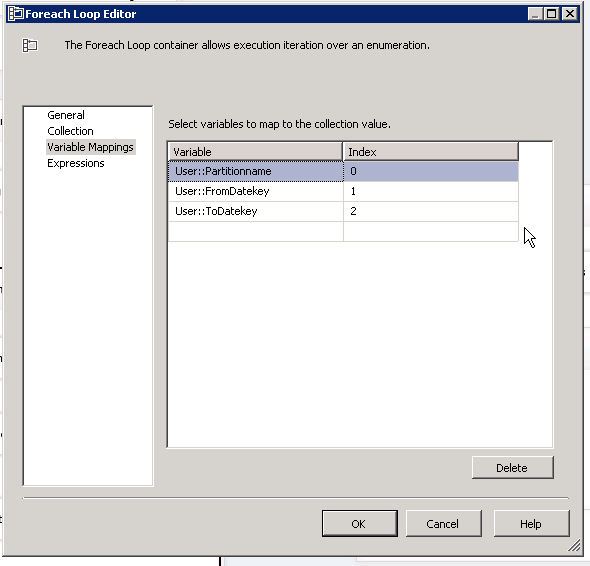
Add a ForeahLoopContainer and define the container to reference the MissingPartitions object as a ADO source and map the data to the variables as below:
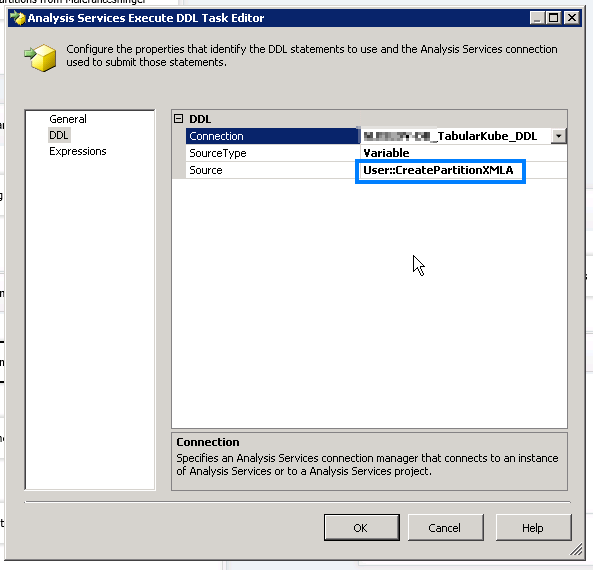
Inside this container add two Analysis Services Execetute DDL Tasks and define a Analysis Services Connectione that matches the environment.
The first DDL (Create Partition) is defined like this:
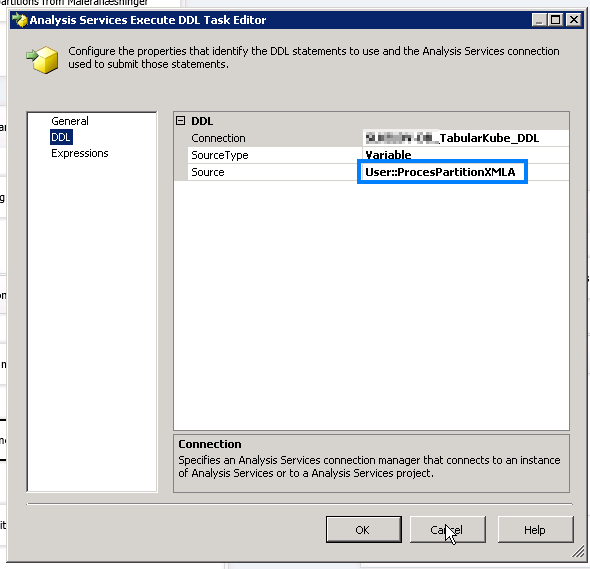
The second DDL (Process Partition) is defined like this:
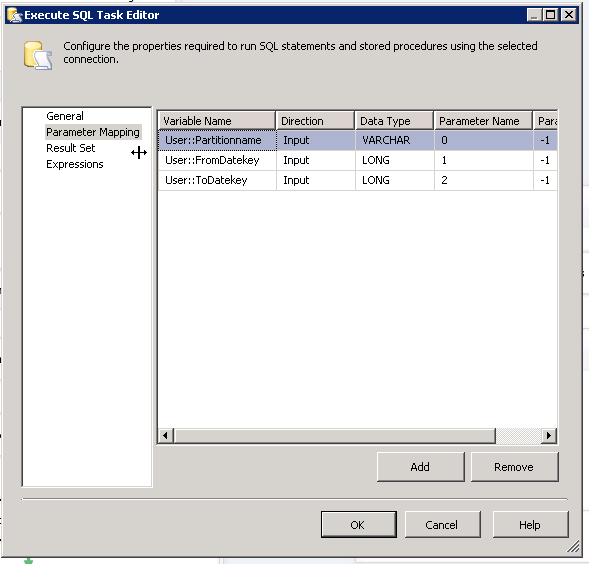
The last step is to add a record in the PartitionLog table – add a SQL task with this statement:
And map the parameters like this:
Now, when the package runs, it will get a dataset of missing partitions, loop the dataset and create and process the partitions dynamically. At the end it creates a record in the partitionlog to keep track of this.
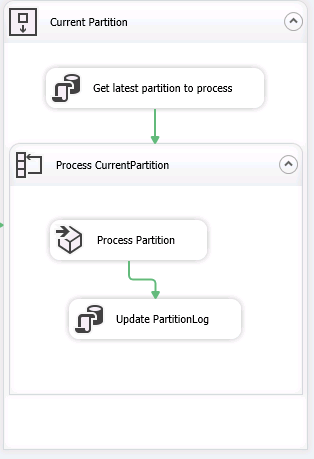
The last thing we need to do is to add a container to process the latest partition every time the package executes.
We need to build this:
Again, add a SQL task and define it to get data from the view with current partition we created earlier:
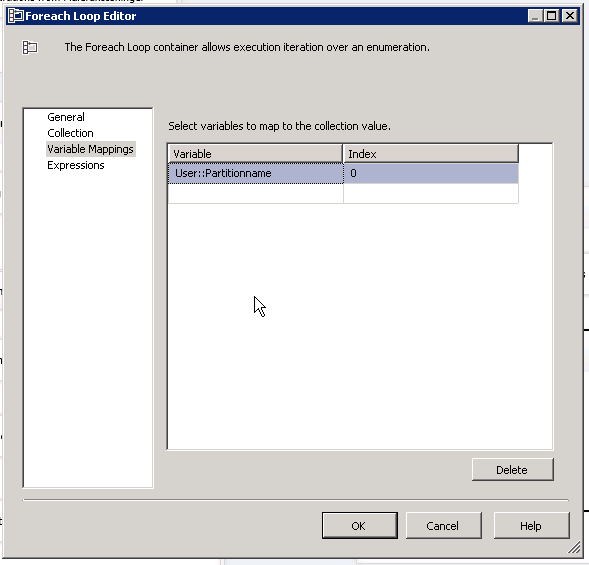
Map the ‘Full resulset’ to the variable PartitionName.
The foreach loop container must be defined to use this variable and the data mapped like this:
Add a Anaysis Services Exectute DDL task and define it to use the variable ProcesPartionXMLA. We can reuse the expression as it is defined as expression and uses the same logic in the expression.
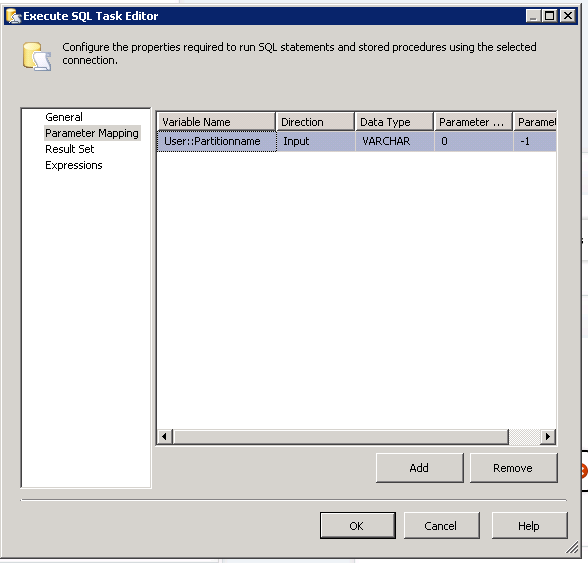
Finally add a SQL task with below code:
Map the parameters like this:
And there it is. All done.
Now every time the package is executed it will see to that missing partitions is created (in this case for every month start) and processed. And it will make sure that the latest partition is updated with the latest data.
The processing time now takes very short time to do, as the only data that is processed is the latest one. Of course the first time the package is run it will create all the partitions and process them.
The whole code from above can be downloaded here:

Subscribe to my channel
")
")
Free Microsoft Workshops
![]()
- Fabric Analyst
- Power BI dashboard
- Real-Time Intelligence